

Too often, we assume that SEO best practices will work in any industry against any competitive set. But most best practices go untested and may not be “best” in every situation.
We all know that tactics that worked in 2020 won’t necessarily move the needle in 2021 as Core Web Vitals (CWV) and other signals shuffle to the front. We have to do better for our businesses and our clients.
I’m a data nerd at heart with lots of battle scars from 15 years in SEO. The idea of analyzing thousands of local SERPs sounded like too much fun to pass up. I found some surprising correlations, and just as importantly, built a methodology and data set that can be updated quarterly to show changes over time.
I analyzed 50,000+ SERPs in the retail banking sector so I could make sense of the massive shifts in rankings and search behaviors during the lockdown period. We have a lot of historical data for bank websites, so comparing pre/post COVID data would be easier than starting from scratch.
I’ll share how I did it below. But first, I want to share WHY I think sharing this type of research is so important for the SEO community.
Why validate SEO best practices with data?
It’s a great time to be an SEO. We have amazing tools and can gather more data than ever. We have thriving communities and excellent basic training materials.
Yet, we often see our craft distilled into overly-simplified “best practices” that are assumed to be universally true. But if there’s one universal truth in SEO, it’s that there are no universal truths. A best practice can be misinterpreted or outdated, leading to missed opportunities or outright harm to a business.
Using the increasing importance of CWV as an example, SEOs have an opportunity (and obligation) to separate fact from fiction. We need to know if, and by how much, CWV will impact rankings over time so we can prioritize our efforts.
We can elevate our SEO game individually and collectively by testing and validating best practices with research. It just takes a curious mind, the right tools, and a willingness to accept the results rather than force a narrative.
Failing to validate best practices is a liability for SEO practitioners and shows an unwillingness to challenge assumptions. In my experience, a lack of data can lead to a senior stakeholders’ opinions carrying more weight than an SEO expert’s recommendations.
Start by asking the right questions
Real insight comes from combining data from multiple sources to answer critical questions and ensure your strategies are backed by valid data. In my analysis of local banks, I started by listing the questions I wanted to know the answers to:
- What characteristics are shared by top-ranking local bank websites?
- Who are banks actually competing against in the SERPs? Is it primarily other banks?
- How do competitive SERPS change based on when/where/how users search?
- How can smaller, local businesses gain an edge over larger competitors from outside their region?
- How does SERP composition affect a bank’s ability to rank well for targeted keywords?
- How important are Core Web Vitals (CWV) for rankings? How does this change over time?
You could run this same analysis by replacing “banks” with other local business categories. The list of potential questions is endless so you can adjust them based on your needs.
Here’s an important reminder – be prepared to accept the answers even if they are inconclusive or contradictory to your assumptions. Data-driven SEOs have to avoid confirmation bias if we’re going to remain objective.
Here’s how I analyzed 50,000 search results in a few hours
I combined three of my favorite tools to analyze SERPs at scale and gather the data needed to answer my questions:
- STAT to generated ranking reports for select keywords
- Screaming Frog to crawl websites and gather technical SEO data
- Power BI to analyze the large data sets and create simple visualizations
Step 1: Determine your data needs
I used US Census Bureau data to identify all cities with populations over 100,000, because I wanted a representation of local bank SERPs across the country. My list ended up including 314 separate cities, but you could customize your list to suit your needs.
I also wanted to gather data for desktop and mobile searches to compare SERP differences between the device types.
Step 2: Identify your keywords
I chose “banks near me” and “banks in {city, st}” based on their strong local intent and high search volumes, compared to more specific keywords for banking services.


Step 3: Generate a STAT import file in .csv format
Once you have your keywords and market list, it’s time to prepare the bulk upload for STAT. Use the template provided in the link to create a .csv file with the following fields:
- Project: The name of the new STAT project, or an existing project.
- Folder: The name of the new folder, or an existing folder. (This is an optional column that you can leave blank.)
- Site: The domain name for the site you want to track. Note, for our purposes you can enter any URL you want to track here. The Top 20 Report will include all ranking URLs for the target keywords even if they aren’t listed in your “Site” column.
- Keyword: The search query you’re adding.
- Tags: Enter as many keyword tags as you want, separated by commas. I used “city” and “near me” as tags to distinguish between the query types. (This is an optional column that you can leave blank.)
- Market: Specify the market (country and language) in which you would like to track the keyword. I used “US-en” for US English.
- Location: If you want to track the keyword in a specific location, specify the city, state, province, ZIP code, and/or postal code. I used the city and state list in “city, st” format.
- Device: Select whether you would like Desktop or Smartphone results. I selected both.
Each market, location, and device type will multiply the number of keywords you must track. I ended up with 1,256 keywords (314 markets X 2 keywords X 2 devices) in my import file.


Once your file is complete, you can import to STAT and begin tracking.
Step 4: Run a Top 20 Report in STAT for all keywords
STAT’s built-in Google SERP Top 20 Comparison report captures the top 20 organic results from each SERP at different intervals (daily, weekly, monthly, etc.) to look at changes over time. I did not need daily data so I simply let it run on two consecutive days and removed the data I did not need. I re-run the same report quarterly to track changes over time.
Watch the video below to learn how to set up this report!
My 1,256 keywords generated over 25,000 rows of data per day. Each row is a different organic listing and includes the keyword, monthly search volume, rank (includes the local pack), base rank (does not include the local pack), https/http protocol of the ranking URL, the ranking URL, and your tags.
Here’s an example of the raw output in CSV format:

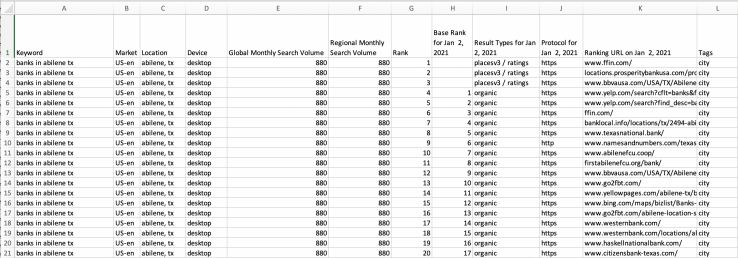
It’s easy to see how useful this data is by itself but it becomes even more powerful when we clean it up and start crawling the ranking URLs.
Step 5: Clean up and normalize your STAT URLs data
At this point you may have invested 1-2 hours in gathering the initial data. This step is a bit more time consuming, but data cleansing allows you to run more advanced analysis and uncover more useful insights in Screaming Frog.
Here are the changes I made to the STAT rankings data to prepare for the next steps in Screaming Frog and Power BI. You’ll end up with multiple columns of URLs. Each serves a purpose later.
- Duplicate the Ranking URL column to a new column called Normalized URL.
- Remove URL parameters from the Normalized URL fields by using Excel’s text to columns tool and separating by “?”. I deleted the new columns(s) containing the URL parameters because they were not helpful in my analysis.
- Duplicate the new, clean Normalized URL column to a new column called TLD. Use the text to columns tool on the TLD column and separate by “/” to remove everything except the domain name and subdomains. Delete the new columns. I chose to keep the subdomains in my TLD column but you can remove them if it helps your analysis.
- Finally, create one more column called Full URL that will eventually become the list of URLs that you’ll crawl in Screaming Frog. To generate the Full URL, simply use Excel’s concatenate function to combine the Protocol and Normalized URL columns. Your formula will look something like this: =concatenate(A1, “://”, C1) to include the “://” in a valid URL string.


The 25,000+ rows in my data set are well within Excel’s limitations, so I am able to manipulate the data easily in one place. You may need to use a database (I like BigQuery) as your data sets grow.
Step 6: Categorize your SERP results by website type
Skimming through the SERP results, it’s easy to see that banks are not the only type of website that rank for keywords with local search intent. Since one of my initial questions was SERP composition, I had to identify all of the different types of websites and label each one for further analysis.
This step is by far the most time consuming and insightful. I spent 3 hours categorizing the initial batch of 25,000+ URLs into one of the following categories:
- Institution (banks and credit union websites)
- Directory (aggregators, local business directories, etc.)
- Reviews (local and national sites like Yelp.com)
- Education (content about banks on .edu domains)
- Government (content about banks on .gov domains and municipal sites)
- Jobs (careers sites and job aggregators)
- News (local and national news sites with banking content)
- Food Banks (yes, plenty of food banks rank for “banks near me” keywords)
- Real Estate (commercial and residential real estate listings)
- Search Engines (ranked content belonging to a search engine)
- Social Media (ranked content on social media sites)
- Other (completely random results not related to any of the above)


Your local SERPs will likely contain many of these website types and other unrelated categories such as food banks. Speed up the process by sorting and filtering your TLD and Normalized URL columns to categorize multiple rows simultaneously. For example, all the yelp.com rankings can be categorized as “Reviews” with a quick copy/paste.
At this point, your rankings data set is complete and you are ready to begin crawling the top-ranking sites in your industry to see what they have in common.
Step 7: Crawl your target websites with Screaming Frog
My initial STAT data identified over 6,600 unique pages from local bank websites that ranked in the top 20 organic search results. This is far too many pages to evaluate manually. Enter Screaming Frog, a crawler that mimics Google’s web crawler and extracts tons of SEO data from websites.
I configured Screaming Frog to crawl each of the 6,600 ranking pages for a larger analysis of characteristics shared by top-ranking bank websites. Don’t just let SF loose though. Be sure to configure it properly to save time and avoid crawling unnecessary pages.
These settings ensure we’ll get all the info we need to answer our questions in one crawl:
List Mode: Paste in a de-duplicated Full URL list from your STAT data. In my case, this was 6,600+ URLs.


Database Storage Mode: It may be a bit slower than Memory (RAM) Storage, but saving your crawl results on your hard disk ensures you won’t lose your results if you make a mistake (like I have many times) and close your report before you finish analyzing the data.

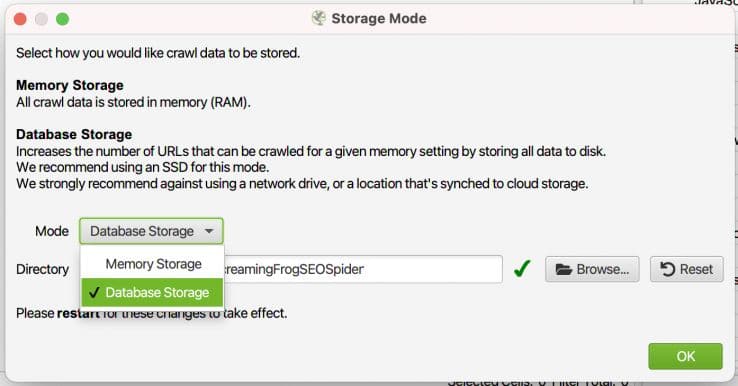
Limit Crawl Depth: Set this to 0 (zero) so the spider will only crawl the URLs on your list without following internal links to other pages on those domains.


APIs: I highly recommend using the Pagespeed Insights Integration to pull Lighthouse speed metrics directly into your crawl data. If you have a Moz account with API access, you can also pull link and domain data from the Moz API with the built-in integration.


Once you have configured the spider, let it rip! It could take several minutes to several hours depending on how many URLs you’re crawling and your computer’s speed and memory constraints. Just be patient! You might try running larger crawls overnight or on an extra computer to avoid bogging your primary machine down.
Step 8: Export your Screaming Frog crawl data to Excel
Dumping your crawl data into Excel is remarkably easy.


Step 9: Join your data sets in Power BI
At this point, you should have two data sources in Excel: one for your STAT rankings data and another for your Screaming Frog crawl data. Our goal is to combine the two data sources to see how organic search rank may be influenced by on-page SEO elements and site performance. To do this, we must first merge the data.
If you have access to a Windows PC, the free version of Power BI is powerful enough to get you started. Begin by loading your two data sources into a new project using the Get Data wizard.

Once your data sets are loaded, it’s time to make the magic happen by creating relationships in your data to unlock correlations between rankings and site characteristics. To combine your data in Power BI, create a many-to-many relationship between your STAT Full URL and Screaming Frog Original URL fields.


If you are new to BI tools and data visualization, don’t worry! There are lots of helpful tutorials and videos just a quick search away. At this point, it’s really hard to break anything and you can experiment with lots of ways to analyze your data and share insights with many types of charts and graphs.
I should note that Power BI is my preferred data visualization tool but you may be able to use Tableau or some equally powerful. Google Data Studio was not an option for this analysis because it only allows for left outer joins of the multiple data sources and does not support “many-to-many” relationships. It’s a technical way of saying Data Studio isn’t flexible enough to create the data relationships that we need.
Step 10: Analyze and visualize!
Power BI’s built-in visualizations allow you to quickly summarize and present data. This is where we can start analyzing the data to answer the questions we came up with earlier.
Results — what did we learn?
Here are a couple examples of the insights gleaned from merging our rankings and crawl data. Spoiler alert — CWV doesn’t strongly impact organic rankings….yet!
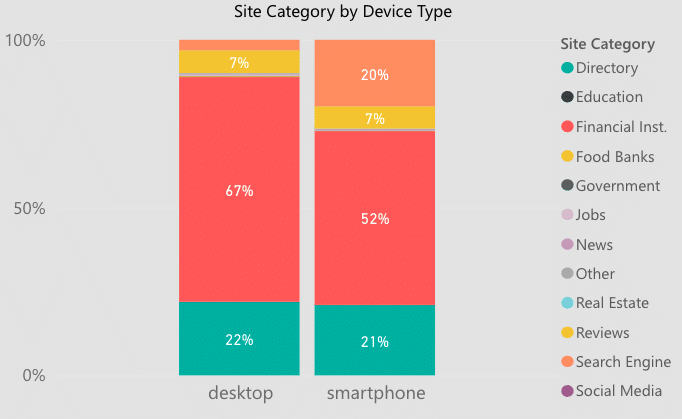
Who are banks actually competing against in the SERPs? Is it primarily other banks?
On desktops, about 67% of organic search results belong to financial institutions (banks and credit unions) with heavy competition from reviews sites (7%) and online directories (22%). This information helps shape our SEO strategies for banks by exposing opportunities to monitor and maintain listings in relevant directories and reviews sites.

Okay, now let’s mash up our data sources to see how the distribution of website categories varies by rank on desktop devices. Suddenly, we can see that financial institutions actually occupy the majority of the top 3 results while reviews sites and directories are more prevalent in positions 4-10.
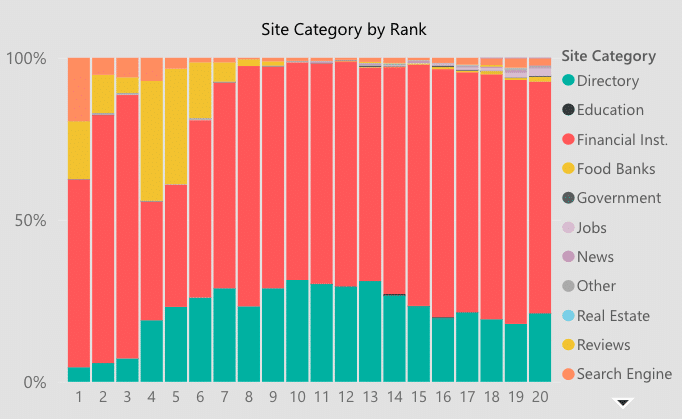
How important are Core Web Vitals (CWV) for rankings? How does this change over time?
Site performance and site speed are hot topics in SEO and will only become more important as CWV becomes a ranking signal in May this year. We can begin to understand the relationships between site speed and rankings by comparing STAT rankings and Pagespeed Insights data from Screaming Frog reports.
As of January 2021, sites with higher Lighthouse Performance Scores (i.e. they load faster) tend to rank better than sites with lower scores. This could help justify investments in site speed and site performance.


Some CWV elements correlate more closely with better rankings and others are more scattered. This isn’t to say CWV aren’t important or meaningful, but rather it’s a starting point for further analysis after May.


So what? What can we learn from this type of analysis?
Separately, STAT and Screaming Frog are incredibly powerful SEO tools. The data they provide are useful if you happen to be an SEO but the ability to merge data and extract relationships will multiply your value in any organization that values data, and acts on insights.
Besides validating some generally accepted SEO knowledge with data (“faster sites are rewarded with better rankings”), better use of relational data can also help us avoid spending valuable time on less important tactics (“improve Cumulative Layout Shift at all costs!”).
Of course, correlation does not imply causation, and aggregated data does not guarantee an outcome for individual sites. But if you’re a bank marketing professional responsible for customer acquisition from organic channels, you’ll need to bring this type of data to your stakeholders to justify increased investments in SEO.
By sharing the tools and methodology, I hope others will take it further by building and contributing their additional findings to the SEO community. What other datasets can we combine to deepen our understanding of SERPs on a larger scale? Let me know your thoughts in the comments!