

Posted by KristinTynski
In my last post, I explained how using network visualization tools can help you massively improve your content marketing PR/Outreach strategy —understanding which news outlets have the largest syndication networks empowers your outreach team to prioritize high-syndication publications over lower syndication publications. The result? The content you are pitching enjoys significantly more widespread link pickups.
Today, I’m going to take you a little deeper — we’ll be looking at a few techniques for forming an even better understanding of the publisher syndication networks in your particular niche. I’ve broken this technique into two parts:
- Technique One — Leveraging Buzzsumo influencer data and twitter scraping to find the most influential journalists writing about any topic
- Technique Two — Leveraging the Gdelt Dataset to reveal deep story syndication networks between publishers using in-context links.
Why do this at all?
If you are interested in generating high-value links at scale, these techniques provide an undeniable competitive advantage — they help you to deeply understand how writers and news publications connect and syndicate to each other.
In our opinion at Fractl, data-driven content stories that have strong news hooks, finding writers and publications who would find the content compelling, and pitching them effectively is the single highest ROI SEO activity possible. Done correctly, it is entirely possible to generate dozens, sometimes even hundreds or thousands, of high-authority links with one or a handful of content campaigns.
Let’s dive in.
Using Buzzsumo to understand journalist influencer networks on any topic
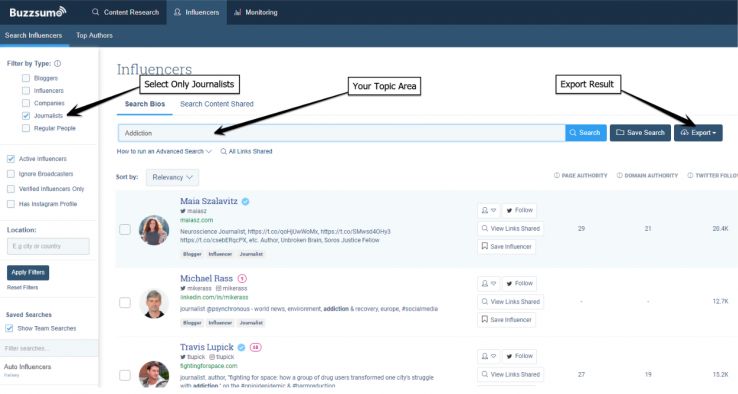
First, you want to figure out who your topc influencers are your a topic. A very handy feature of Buzzsumo is its “influencers” tool. You can locate it on the influences tab, then follow these steps:
- Select only “Journalists.” This will limit the result to only the Twitter accounts of those known to be reporters and journalists of major publications. Bloggers and lower authority publishers will be excluded.
- Search using a topical keyword. If it is straightforward, one or two searches should be fine. If it is more complex, create a few related queries, and collate the twitter accounts that appear in all of them. Alternatively, use the Boolean “and/or” in your search to narrow your result. It is critical to be sure your search results are returning journalists that as closely match your target criteria as possible.
- Ideally, you want at least 100 results. More is generally better, so long as you are sure the results represent your target criteria well.
- Once you are happy with your search result, click export to grab a CSV.

The next step is to grab all of the people each of these known journalist influencers follows — the goal is to understand which of these 100 or so influencers impacts the other 100 the most. Additionally, we want to find people outside of this group that many of these 100 follow in common.
To do so, we leveraged Twint, a handy Twitter scraper available on Github to pull all of the people each of these journalist influencers follow. Using our scraped data, we built an edge list, which allowed us to visualize the result in Gephi.
Here is an interactive version for you to explore, and here is a screenshot of what it looks like:

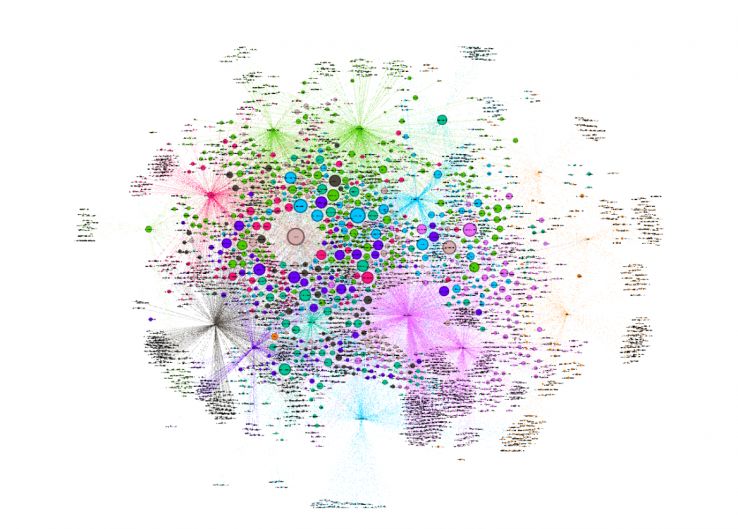
This graph shows us which nodes (influencers) have the most In-Degree links. In other words: it tells us who, of our media influencers, is most followed.
These are the top 10 nodes:
- Maia Szalavitz (@maiasz) Neuroscience Journalist, VICE and TIME
- Radley Balko (@radleybalko) Opinion journalist, Washington Post
- Johann Hari (@johannhari101) New York Times best-selling author
- David Kroll (@davidkroll) Freelance healthcare writer, Forbes Heath
- Max Daly (@Narcomania) Global Drugs Editor, VICE
- Dana Milbank (@milbank)Columnist, Washington Post
- Sam Quinones (@samquinones7), Author
- Felice Freyer (@felicejfreyer), Boston Globe Reporter, Mental health and Addiction
- Jeanne Whalen (@jeannewhalen) Business Reporter, Washington Post
- Eric Bolling (@ericbolling) New York Times best-selling author
Who is the most influential?
Using the “Betweenness Centrality” score given by Gephi, we get a rough understanding of which nodes (influencers) in the network act as hubs of information transfer. Those with the highest “Betweenness Centrality” can be thought of as the “connectors” of the network. These are the top 10 influencers:
- Maia Szalavitz (@maiasz) Neuroscience Journalist, VICE and TIME
- David Kroll (@davidkroll) Freelance healthcare writer, Forbes Heath
- Jeanne Whalen (@jeannewhalen) Business Reporter, Washington Post
- Travis Lupick (@tlupick), Journalist, Author
- Johann Hari (@johannhari101) New York Times best-selling author
- Radley Balko (@radleybalko) Opinion journalist, Washington Post
- Sam Quinones (@samquinones7), Author
- Eric Bolling (@ericbolling) New York Times best-selling author
- Dana Milbank (@milbank)Columnist, Washington Post
- Mike Riggs (@mikeriggs) Writer & Editor, Reason Mag
@maiasz, @davidkroll, and @johannhari101 are standouts. There’s considerable overlap between the winners in “In-Degree” and “Betweenness Centrality” but they are still quite different.
What else can we learn?
The middle of the visualization holds many of the largest sized nodes. The nodes in this view are sized by “In-Degree.” The large, centrally located nodes are disproportionately followed by other members of the graph and enjoy popularity across the board (from many of the other influential nodes). These are journalists commonly followed by everyone else. Sifting through these centrally located nodes will surface many journalists who behave as influencers of the group initially pulled from BuzzSumo.
So, if you had a campaign about a niche topic, you could consider pitching to an influencer surfaced from this data —according to our the visualization, an article shared in their network would have the most reach and potential ROI
Using Gdelt to find the most influential websites on a topic with in-context link analysis
The first example was a great way to find the best journalists in a niche to pitch to, but top journalists are often the most pitched to overall. Often times, it can be easier to get a pickup from less known writers at major publications. For this reason, understanding which major publishers are most influential, and enjoy the widest syndication on a specific theme, topic, or beat, can be majorly helpful.
By using Gdelt’s massive and fully comprehensive database of digital news stories, along with Google BigQuery and Gephi, it is possible to dig even deeper to yield important strategic information that will help you prioritize your content pitching.
We pulled all of the articles in Gdelt’s database that are known to be about a specific theme within a given timeframe. In this case (as with the previous example) we looked at “behaviour health.” For each article we found in Gdelt’s database that matches our criteria, we also grabbed links found only within the context of the article.
Here is how it is done:
- Connect to Gdelt on Google BigQuery — you can find a tutorial here.
- Pull data from Gdelt. You can use this command: SELECT DocumentIdentifier,V2Themes,Extras,SourceCommonName,DATE FROM [gdelt-bq:gdeltv2.gkg] where (V2Themes like ‘%Your Theme%’).
- Select any theme you find, here — just replace the part between the percentages.
- To extract the links found in each article and build an edge file. This can be done with a relatively simple python script to pull out all of the from the results of the query, clean the links to only show their root domain (not the full URL) and put them into an edge file format.
Note: The edge file is made up of Source–>Target pairs. The Source is the article and the Target are the links found within the article. The edge list will look like this:
- Article 1, First link found in the article.
- Article 1, Second link found in the article.
- Article 2, First link found in the article.
- Article 2, Second link found in the article.
- Article 2, Third link found in the article.
From here, the edge file can be used to build a network visualization where the nodes publishers and the edges between them represent the in-context links found from our Gdelt data pull around whatever topic we desired.
This final visualization is a network representation of the publishers who have written stories about addiction, and where those stories link to.


What can we learn from this graph?
This tells us which nodes (Publisher websites) have the most In-Degree links. In other words: who is the most linked. We can see that the most linked-to for this topic are:
- tmz.com
- people.com
- cdc.gov
- cnn.com
- go.com
- nih.gov
- ap.org
- latimes.com
- jamanetwork.com
- nytimes.com
Which publisher is most influential?
Using the “Betweenness Centrality” score given by Gephi, we get a rough understanding of which nodes (publishers) in the network act as hubs of information transfer. The nodes with the highest “Betweenness Centrality” can be thought of as the “connectors” of the network. Getting pickups from these high-betweenness centrality nodes gives a much greater likelihood of syndication for that specific topic/theme.
- Dailymail.co.uk
- Nytimes.com
- People.com
- CNN.com
- Latimes.com
- washingtonpost.com
- usatoday.com
- cvslocal.com
- huffingtonpost.com
- sfgate.com
What else can we learn?
Similar to the first example, the higher the betweenness centrality numbers, number of In-degree links, and the more centrally located in the graph, the more “important” that node can generally be said to be. Using this as a guide, the most important pitching targets can be easily identified.
Understanding some of the edge clusters gives additional insights into other potential opportunities. Including a few clusters specific to different regional or state local news, and a few foreign language publication clusters.
Wrapping up
I’ve outlined two different techniques we use at Fractl to understand the influence networks around specific topical areas, both in terms of publications and the writers at those publications. The visualization techniques described are not obvious guides, but instead, are tools for combing through large amounts of data and finding hidden information. Use these techniques to unearth new opportunities and prioritize as you get ready to find the best places to pitch the content you’ve worked so hard to create.
Do you have any similar ideas or tactics to ensure you’re pitching the best writers and publishers with your content? Comment below!
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don’t have time to hunt down but want to read!
![]()
