
Posted by sergeystefoglo
If your work involves SEO at some level, you’ve most likely been hearing more and more about JavaScript and the implications it has on crawling and indexing. Frankly, Googlebot struggles with it, and many websites utilize modern-day JavaScript to load in crucial content today. Because of this, we need to be equipped to discuss this topic when it comes up in order to be effective.
The goal of this post is to equip you with the minimum viable knowledge required to do so. This post won’t go into the nitty gritty details, describe the history, or give you extreme detail on specifics. There are a lot of incredible write-ups that already do this — I suggest giving them a read if you are interested in diving deeper (I’ll link out to my favorites at the bottom).
In order to be effective consultants when it comes to the topic of JavaScript and SEO, we need to be able to answer three questions:
- Does the domain/page in question rely on client-side JavaScript to load/change on-page content or links?
- If yes, is Googlebot seeing the content that’s loaded in via JavaScript properly?
- If not, what is the ideal solution?
With some quick searching, I was able to find three examples of landing pages that utilize JavaScript to load in crucial content.
I’m going to be using Sitecore’s Symposium landing page through each of these talking points to illustrate how to answer the questions above.
We’ll cover the “how do I do this” aspect first, and at the end I’ll expand on a few core concepts and link to further resources.
Question 1: Does the domain in question rely on client-side JavaScript to load/change on-page content or links?
The first step to diagnosing any issues involving JavaScript is to check if the domain uses it to load in crucial content that could impact SEO (on-page content or links). Ideally this will happen anytime you get a new client (during the initial technical audit), or whenever your client redesigns/launches new features of the site.
How do we go about doing this?
Ask the client
Ask, and you shall receive! Seriously though, one of the quickest/easiest things you can do as a consultant is contact your POC (or developers on the account) and ask them. After all, these are the people who work on the website day-in and day-out!
“Hi [client], we’re currently doing a technical sweep on the site. One thing we check is if any crucial content (links, on-page content) gets loaded in via JavaScript. We will do some manual testing, but an easy way to confirm this is to ask! Could you (or the team) answer the following, please?
1. Are we using client-side JavaScript to load in important content?
2. If yes, can we get a bulleted list of where/what content is loaded in via JavaScript?”
Check manually
Even on a large e-commerce website with millions of pages, there are usually only a handful of important page templates. In my experience, it should only take an hour max to check manually. I use the Chrome Web Developers plugin, disable JavaScript from there, and manually check the important templates of the site (homepage, category page, product page, blog post, etc.)

In the example above, once we turn off JavaScript and reload the page, we can see that we are looking at a blank page.
As you make progress, jot down notes about content that isn’t being loaded in, is being loaded in wrong, or any internal linking that isn’t working properly.
At the end of this step we should know if the domain in question relies on JavaScript to load/change on-page content or links. If the answer is yes, we should also know where this happens (homepage, category pages, specific modules, etc.)
Crawl
You could also crawl the site (with a tool like Screaming Frog or Sitebulb) with JavaScript rendering turned off, and then run the same crawl with JavaScript turned on, and compare the differences with internal links and on-page elements.
For example, it could be that when you crawl the site with JavaScript rendering turned off, the title tags don’t appear. In my mind this would trigger an action to crawl the site with JavaScript rendering turned on to see if the title tags do appear (as well as checking manually).
Example
For our example, I went ahead and did a manual check. As we can see from the screenshot below, when we disable JavaScript, the content does not load.
In other words, the answer to our first question for this pages is “yes, JavaScript is being used to load in crucial parts of the site.”
Question 2: If yes, is Googlebot seeing the content that’s loaded in via JavaScript properly?
If your client is relying on JavaScript on certain parts of their website (in our example they are), it is our job to try and replicate how Google is actually seeing the page(s). We want to answer the question, “Is Google seeing the page/site the way we want it to?”
In order to get a more accurate depiction of what Googlebot is seeing, we need to attempt to mimic how it crawls the page.
How do we do that?
Use Google’s new mobile-friendly testing tool
At the moment, the quickest and most accurate way to try and replicate what Googlebot is seeing on a site is by using Google’s new mobile friendliness tool. My colleague Dom recently wrote an in-depth post comparing Search Console Fetch and Render, Googlebot, and the mobile friendliness tool. His findings were that most of the time, Googlebot and the mobile friendliness tool resulted in the same output.
In Google’s mobile friendliness tool, simply input your URL, hit “run test,” and then once the test is complete, click on “source code” on the right side of the window. You can take that code and search for any on-page content (title tags, canonicals, etc.) or links. If they appear here, Google is most likely seeing the content.
Search for visible content in Google
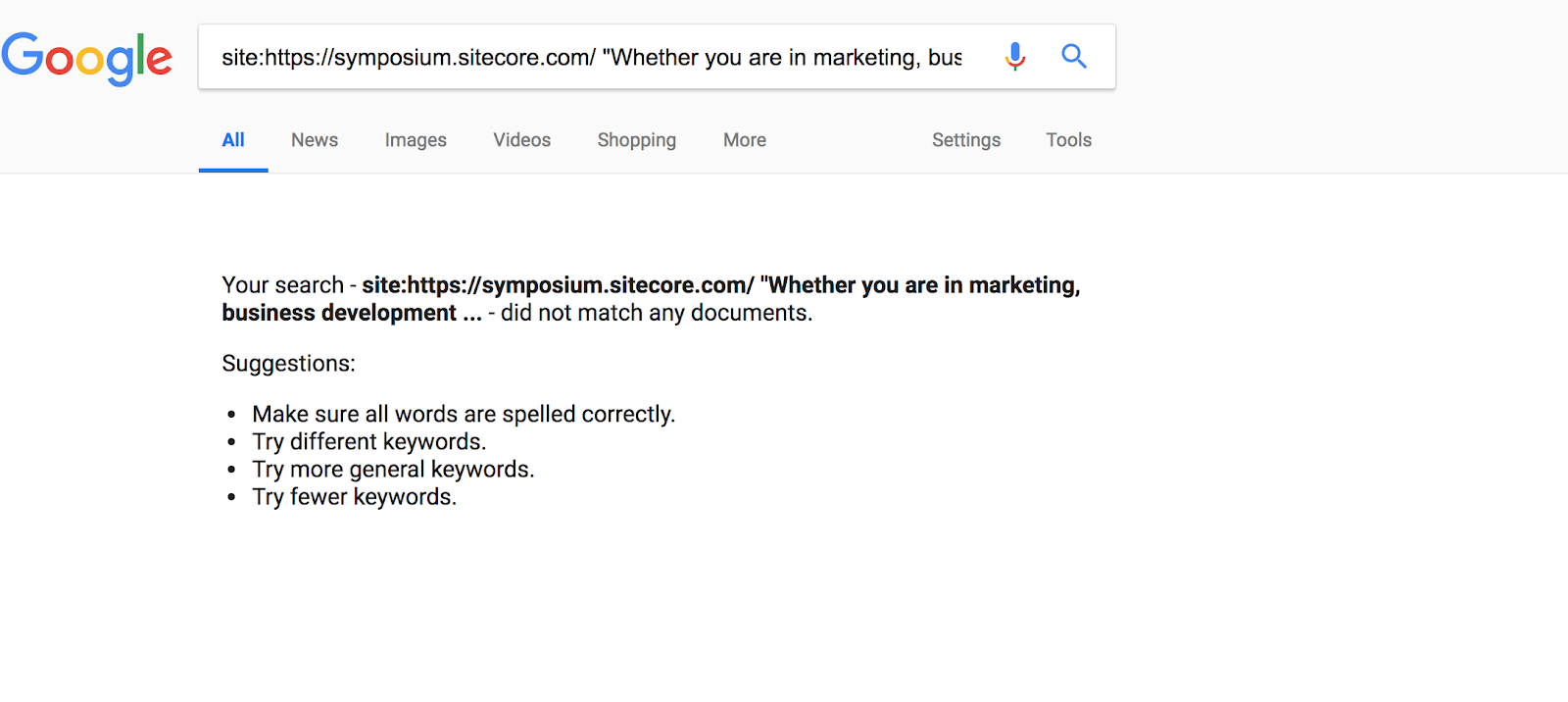
It’s always good to sense-check. Another quick way to check if GoogleBot has indexed content on your page is by simply selecting visible text on your page, and doing a site:search for it in Google with quotations around said text.
In our example there is visible text on the page that reads…
“Whether you are in marketing, business development, or IT, you feel a sense of urgency. Or maybe opportunity?”
When we do a site:search for this exact phrase, for this exact page, we get nothing. This means Google hasn’t indexed the content.
 Crawling with a tool
Crawling with a tool
 Crawling with a tool
Crawling with a toolMost crawling tools have the functionality to crawl JavaScript now. For example, in Screaming Frog you can head to configuration > spider > rendering > then select “JavaScript” from the dropdown and hit save. DeepCrawl and SiteBulb both have this feature as well.
From here you can input your domain/URL and see the rendered page/code once your tool of choice has completed the crawl.
Example:
When attempting to answer this question, my preference is to start by inputting the domain into Google’s mobile friendliness tool, copy the source code, and searching for important on-page elements (think title tag,
, body copy, etc.) It’s also helpful to use a tool like diff checker to compare the rendered HTML with the original HTML (Screaming Frog also has a function where you can do this side by side).
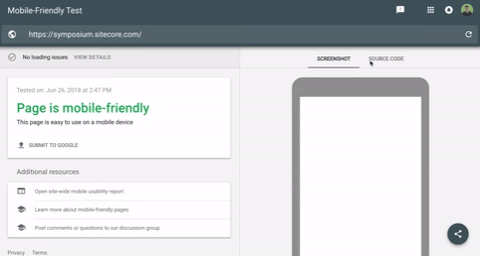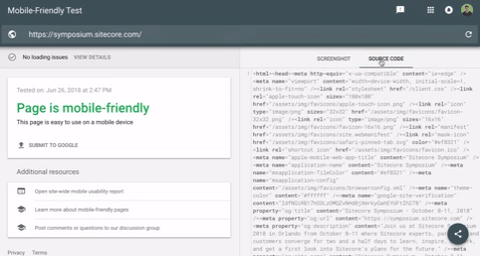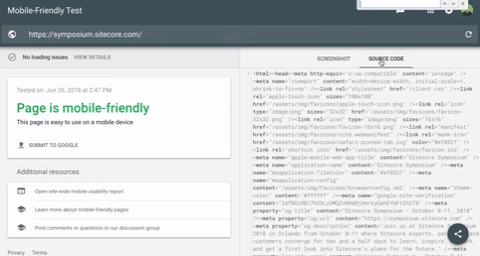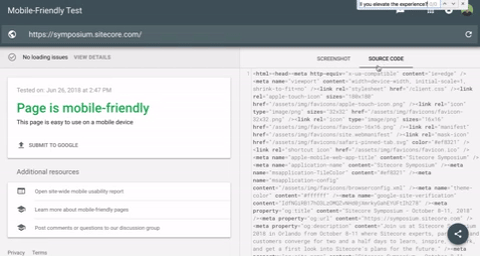
For our example, here is what the output of the mobile friendliness tool shows us.
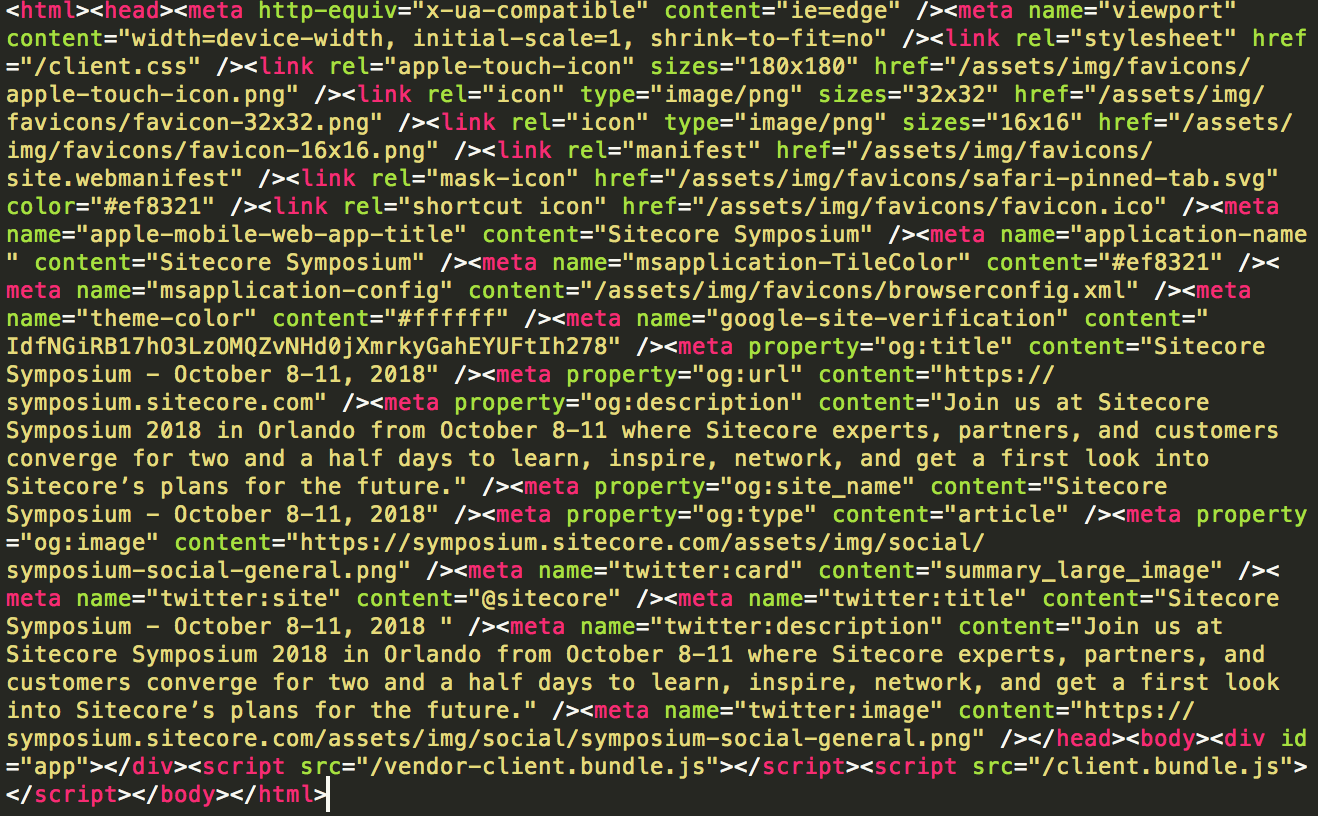
After a few searches, it becomes clear that important on-page elements are missing here.
We also did the second test and confirmed that Google hasn’t indexed the body content found on this page.
The implication at this point is that Googlebot is not seeing our content the way we want it to, which is a problem.
Let’s jump ahead and see what we can recommend the client.
Question 3: If we’re confident Googlebot isn’t seeing our content properly, what should we recommend?
Now we know that the domain is using JavaScript to load in crucial content and we know that Googlebot is most likely not seeing that content, the final step is to recommend an ideal solution to the client. Key word: recommend, not implement. It’s 100% our job to flag the issue to our client, explain why it’s important (as well as the possible implications), and highlight an ideal solution. It is 100% not our job to try to do the developer’s job of figuring out an ideal solution with their unique stack/resources/etc.
How do we do that?
You want server-side rendering
The main reason why Google is having trouble seeing Sitecore’s landing page right now, is because Sitecore’s landing page is asking the user (us, Googlebot) to do the heavy work of loading the JavaScript on their page. In other words, they’re using client-side JavaScript.
Googlebot is literally landing on the page, trying to execute JavaScript as best as possible, and then needing to leave before it has a chance to see any content.
The fix here is to instead have Sitecore’s landing page load on their server. In other words, we want to take the heavy lifting off of Googlebot, and put it on Sitecore’s servers. This will ensure that when Googlebot comes to the page, it doesn’t have to do any heavy lifting and instead can crawl the rendered HTML.
In this scenario, Googlebot lands on the page and already sees the HTML (and all the content).
There are more specific options (like isomorphic setups)
This is where it gets to be a bit in the weeds, but there are hybrid solutions. The best one at the moment is called isomorphic.
In this model, we’re asking the client to load the first request on their server, and then any future requests are made client-side.
So Googlebot comes to the page, the client’s server has already executed the initial JavaScript needed for the page, sends the rendered HTML down to the browser, and anything after that is done on the client-side.
If you’re looking to recommend this as a solution, please read this post from the AirBNB team which covers isomorphic setups in detail.
AJAX crawling = no go
I won’t go into details on this, but just know that Google’s previous AJAX crawling solution for JavaScript has since been discontinued and will eventually not work. We shouldn’t be recommending this method.
(However, I am interested to hear any case studies from anyone who has implemented this solution recently. How has Google responded? Also, here’s a great write-up on this from my colleague Rob.)
Summary
At the risk of severely oversimplifying, here’s what you need to do in order to start working with JavaScript and SEO in 2018:
- Know when/where your client’s domain uses client-side JavaScript to load in on-page content or links.
- Ask the developers.
- Turn off JavaScript and do some manual testing by page template.
- Crawl using a JavaScript crawler.
- Check to see if GoogleBot is seeing content the way we intend it to.
- Google’s mobile friendliness checker.
- Doing a site:search for visible content on the page.
- Crawl using a JavaScript crawler.
- Give an ideal recommendation to client.
- Server-side rendering.
- Hybrid solutions (isomorphic).
- Not AJAX crawling.
Further resources
- The Ultimate Guide to JavaScript SEO
- JavaScript and SEO: The Difference Between Crawling and Indexing
- Core Principles of SEO for JavaScript
- How to Audit JavaScript for SEO
- JavaScript SEO Resources
- View Source: Why it Still Matters and How to Quickly Compare it to a Rendered DOM
I’m really interested to hear about any of your experiences with JavaScript and SEO. What are some examples of things that have worked well for you? What about things that haven’t worked so well? If you’ve implemented an isomorphic setup, I’m curious to hear how that’s impacted how Googlebot sees your site.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don’t have time to hunt down but want to read!
![]()